The Problem
Nitrogen fertilizer recommendations for corn usually rely on simplified regional guidelines that ignore the interactions between soil, weather, and management. Under-fertilization costs yield; over-fertilization costs money and harms the environment. What an agronomist actually needs is a site-specific dose–response curve — how yield responds to nitrogen on a given field — together with an honest statement of how much that curve can be trusted.
The Approach
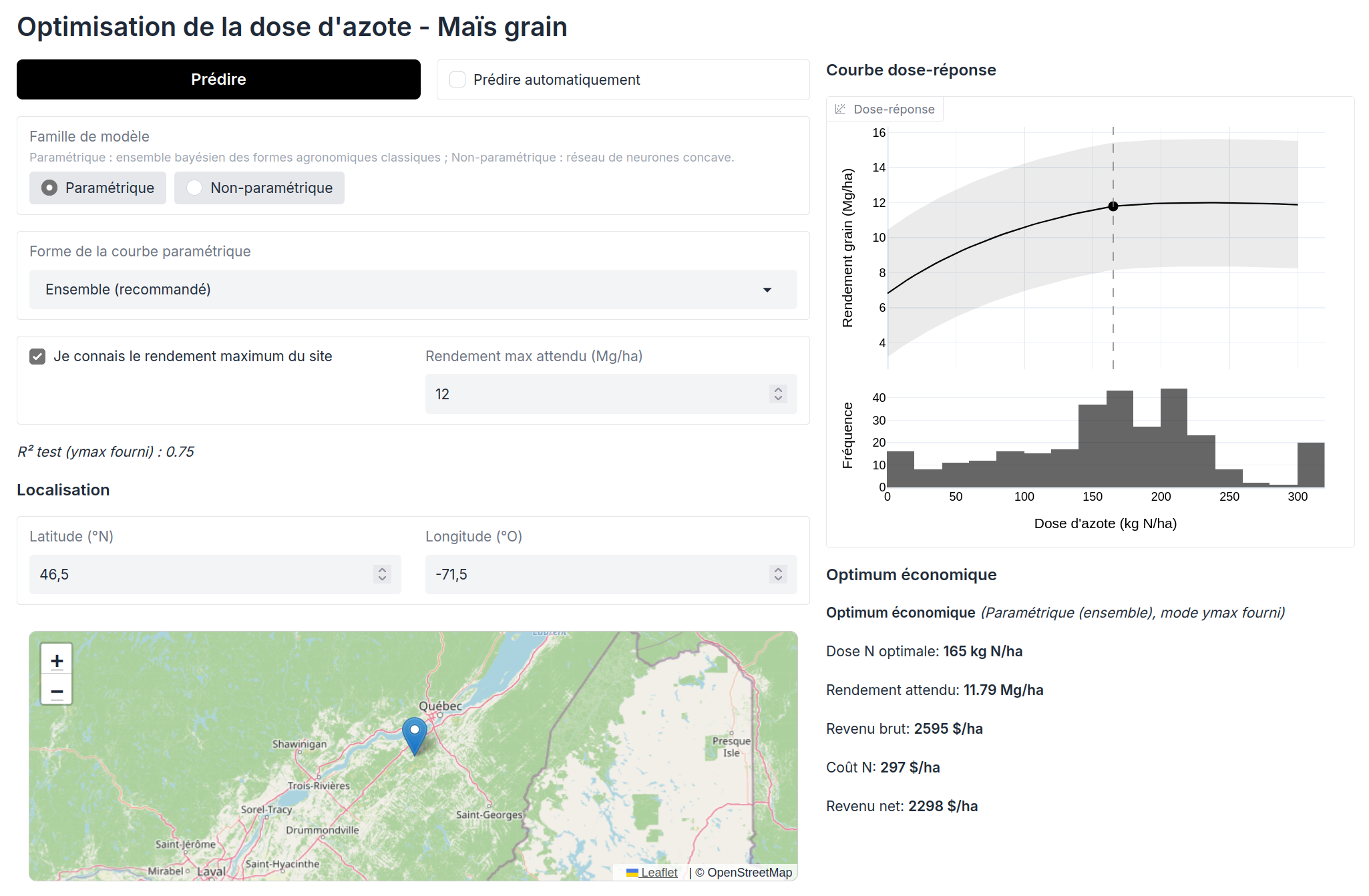
This ongoing client project models the corn nitrogen dose–response by pairing canonical agronomic forms (Mitscherlich, linear-plateau, quadratic-plateau) with modern statistical learning. Rather than predicting yield in a single black-box step, the model separates two physically distinct sources of variation — the site’s yield potential and the shape of its response to nitrogen — and recombines them. This mirrors how the system actually behaves and avoids the failure mode of brute-force regression on absolute yield.
Two operating modes are supported and reported separately:
- Blind: prediction from site features alone — what to expect on a new field with no prior observations
- Agronomist-assisted: the agronomist supplies the expected site potential, which anchors the scale of the curve
Technical Implementation
- Canonical agronomic response forms used as a structural prior
- A multi-task Gaussian process (coregionalization) and a concave, plateau-constrained neural network for the response shape
- Separate prediction of site potential, combined multiplicatively with the response shape
- Conformal calibration for honest, distribution-free prediction intervals
- Project-stratified train/test splitting and strict avoidance of data leakage
- Interactive interface (Gradio) for agronomists to explore scenarios
- Deployment with a Docker container
Current Status
Ongoing client engagement. The modeling pipeline is functional and validated under a leakage-free, project-stratified protocol, with uncertainty reported alongside every prediction. One finding is deliberately honest rather than flattering: in blind mode, achievable accuracy is bounded by what the available site features permit, not by the choice of algorithm. Pushing further calls for richer site signals — yield history, in-season or satellite observations — rather than a more elaborate model.